Spatial Gene Expression Prediction Tutorial (Human Breast Cancer)
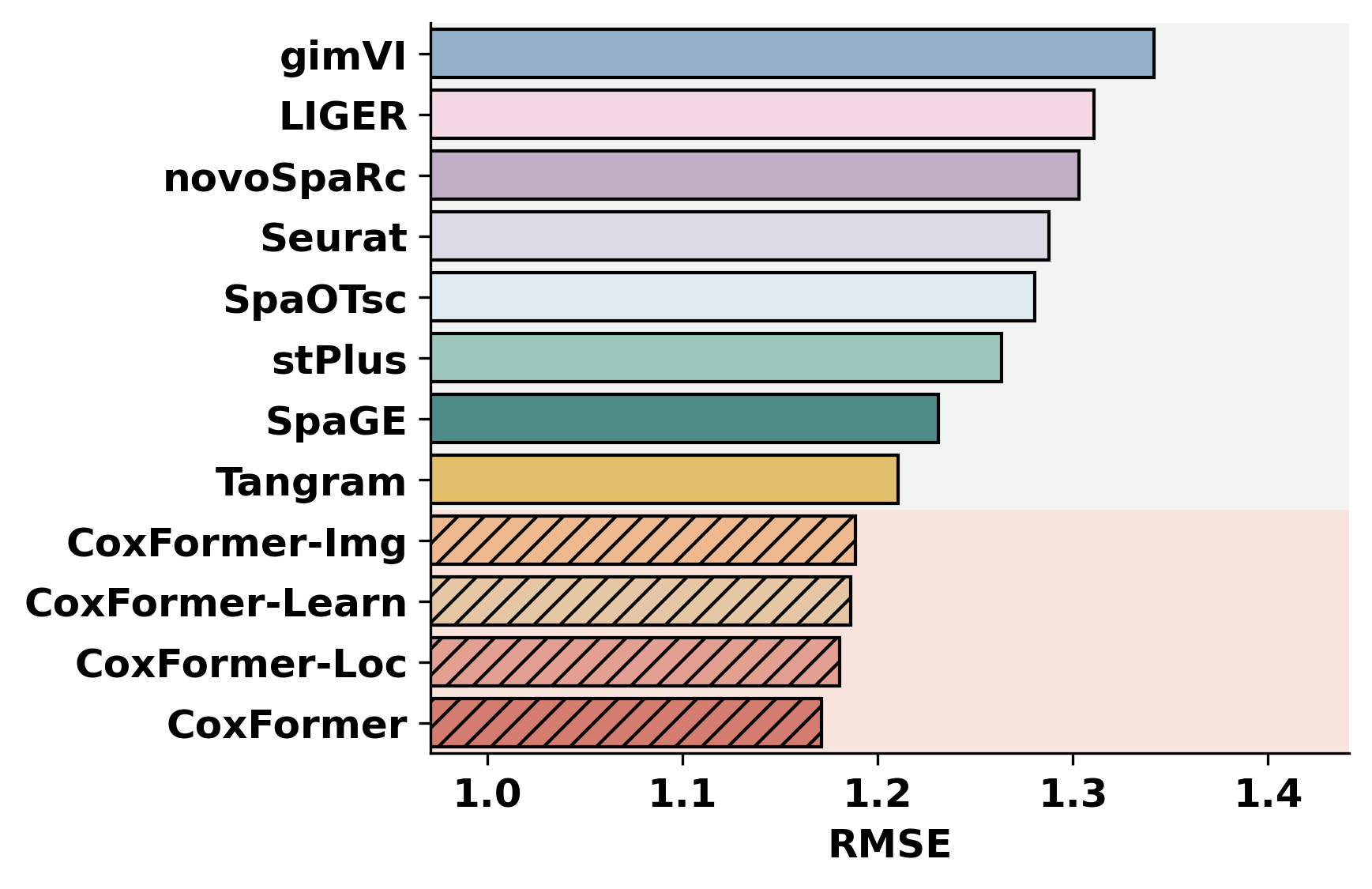
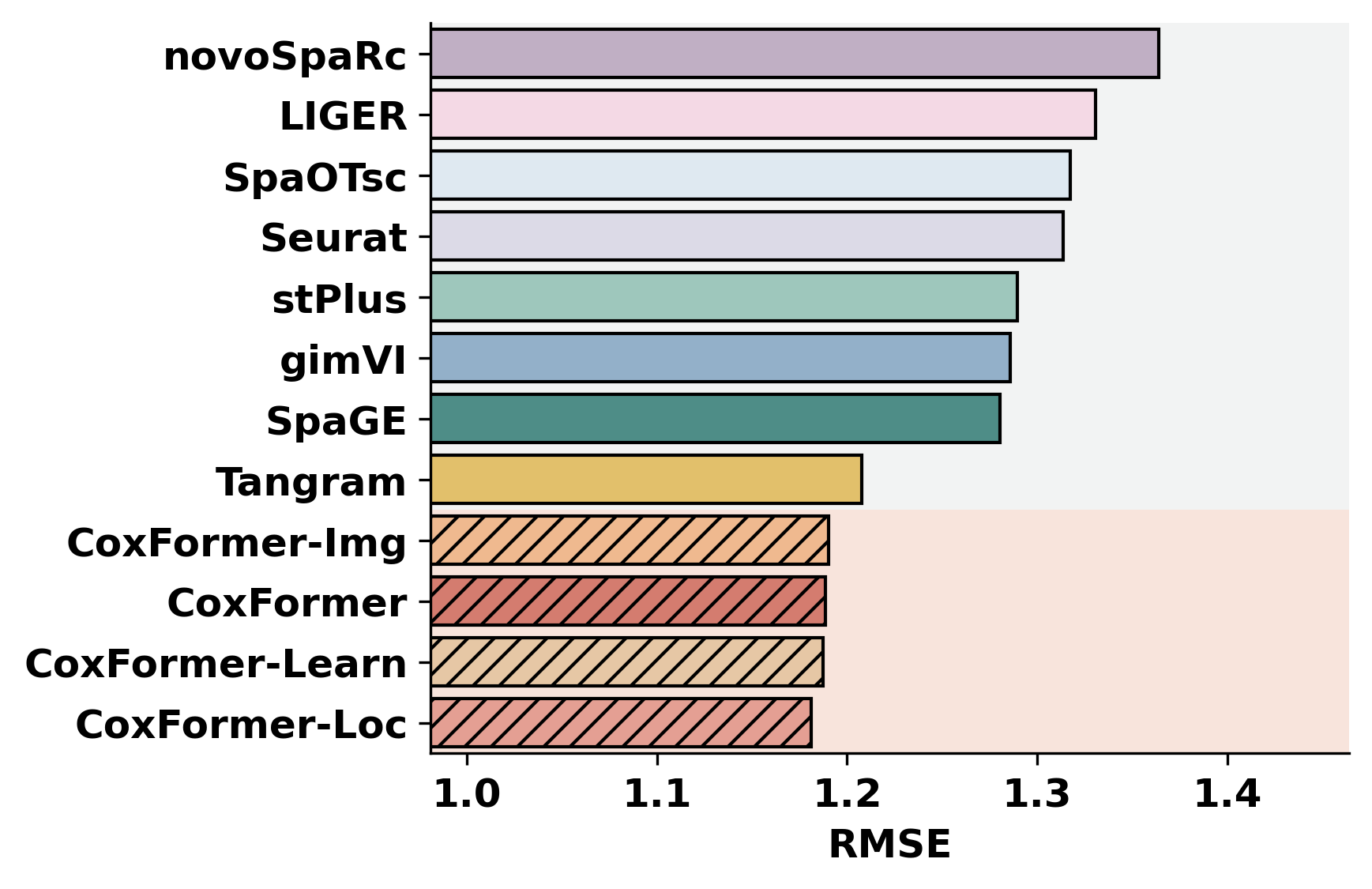
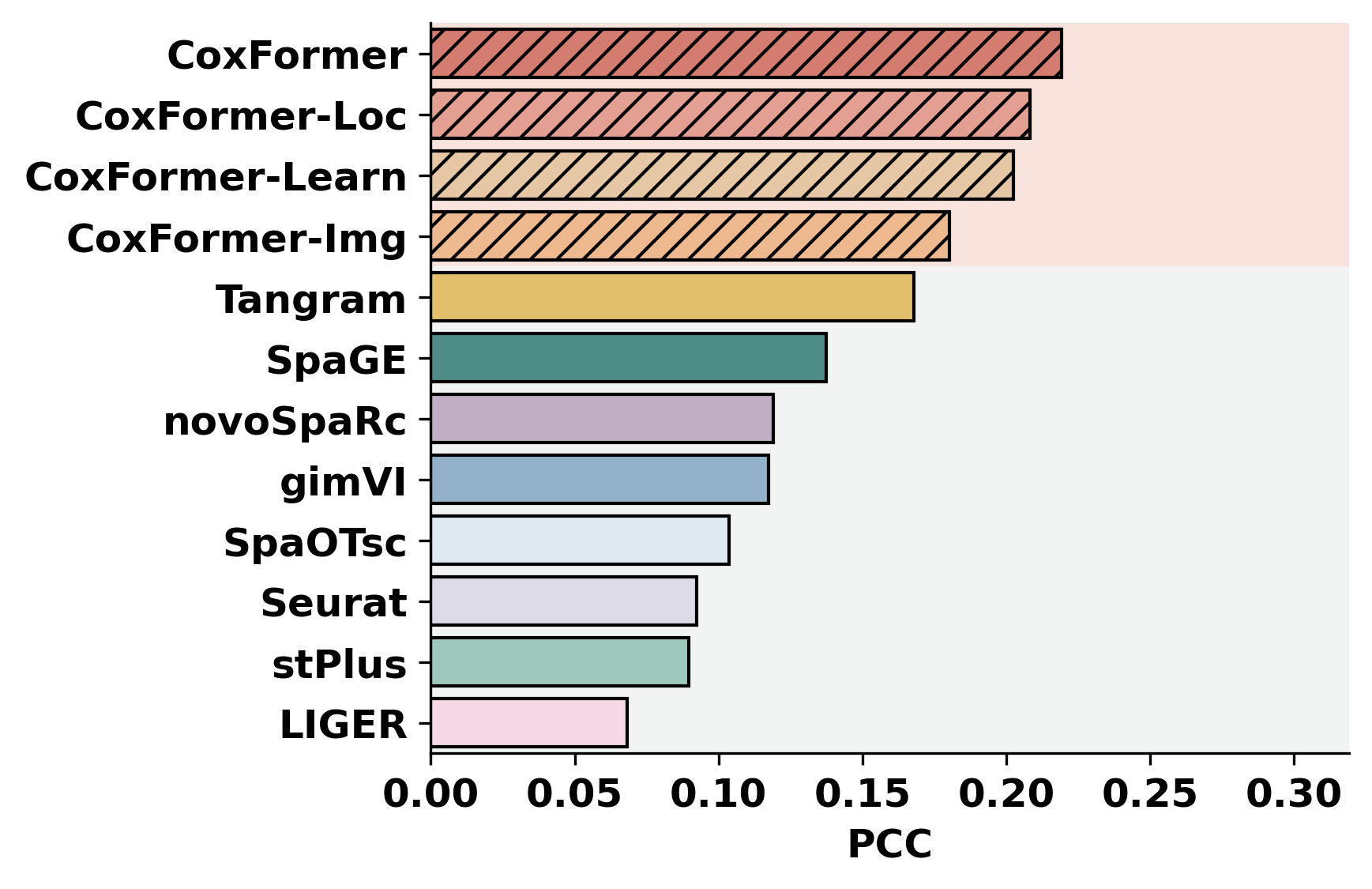
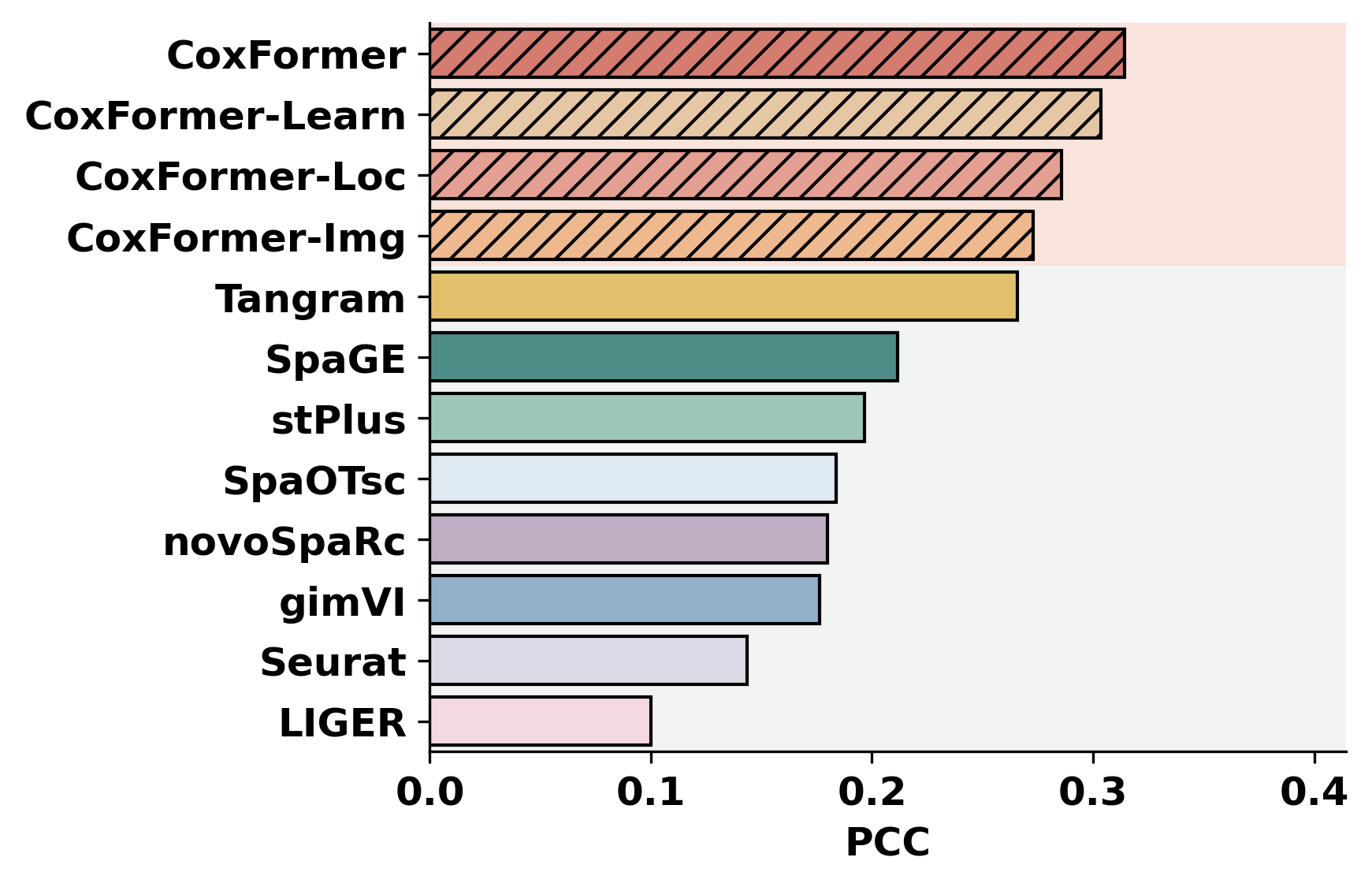
This tutorial evaluates spatial transcripts imputation on the Human Breast Cancer dataset by comparing the ground truth matrix to nine imputed results (e.g., CoxFormer, Tangram, SpaGE, stPlus, gimVI, novoSpaRc, LIGER, Seurat , SpaOTsc).
The notebook includes:
Metric computation and a Bar Plot across methods (e.g., PCC, SSIM, RMSE).
Spatial visualization of selected genes to compare spatial patterns between ground truth and imputations.
All functions are available in utils/.
0. Configuration
Define the dataset module (e.g., Human Breast Cancer) and set the paths:
DATA_PATH: input data directory (e.g.,meta.tsv,cnts.tsv,locs.tsv)RES_PATH: imputation results and evaluation outputs (e.g.,{tool}_impute.csv,{tool}_Metrics.txt)
[1]:
import os
import pandas as pd
os.chdir(os.path.abspath(".."))
from utils.Gene_expression_prediction_utils import CalDataMetric, plot_bar_benchmark, plot_gene_spatial
[2]:
datasets = ["HBC1", "HBC2", "HBC3", "HBC4", "HBC5", "HBC6"]
RES_PATH = "Result/Gene_expression_prediction"
DATA_PATH = "Dataset/Gene_expression_prediction"
1. Metric computation (optional)
This section computes evaluation metrics for each dataset and each method, using a consistent gene set shared by ground truth and predictions.
If you already have metric files written under each
Result/ScRNA/Dataset{ID}/, you can skip this section.The implementation relies on
CalDataMetricprovided inutils.py.
[ ]:
for dataset in datasets:
dataset_path = os.path.join(RES_PATH, f"{dataset}")
CalDataMetric(dataset_path, os.path.join(dataset_path, "groundtruth.csv"))
Result/ScRNA/Dataset20/GenePT-Img_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset20/GenePT_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset20/GenePT-Learn_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset20/GenePT-Loc_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset21/GenePT-Img_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset21/GenePT_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset21/GenePT-Learn_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset21/GenePT-Loc_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset22/GenePT-Img_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset22/GenePT_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset22/GenePT-Learn_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset22/GenePT-Loc_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset23/GenePT-Img_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset23/GenePT_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset23/GenePT-Learn_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset23/GenePT-Loc_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset24/GenePT-Img_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset24/GenePT_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset24/GenePT-Learn_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset24/GenePT-Loc_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset25/GenePT-Img_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset25/GenePT_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset25/GenePT-Learn_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
Result/ScRNA/Dataset25/GenePT-Loc_impute.csv
/project2/wangshu/yangyy/COPT/Part2/0_Sum_Task/utils.py:145: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support sep=None with delim_whitespace=False; you can avoid this warning by specifying engine='python'.
self.raw_count = pd.read_csv(raw_count_file, header = 0, sep=None)
2. Cross-dataset benchmarking
This section summarizes a selected metric across datasets for all methods. It assumes each dataset folder contains metric outputs produced by the previous step (or by an external pipeline).
[ ]:
paths = [os.path.join(RES_PATH, f"{dataset}") + os.sep for dataset in datasets]
methods = ["CoxFormer","CoxFormer-Learn","CoxFormer-Img","CoxFormer-Loc", "SpaGE", "Tangram", "stPlus", "gimVI", "novoSpaRc", "LIGER", "Seurat", "SpaOTsc"]
metrics = ["RMSE","PCC","SSIM"]
idx = 0
for metric_name in metrics:
for path in paths:
plot_bar_benchmark([path], metric_name, methods, RES_PATH, f"HBC{idx}", False)
idx = idx + 1
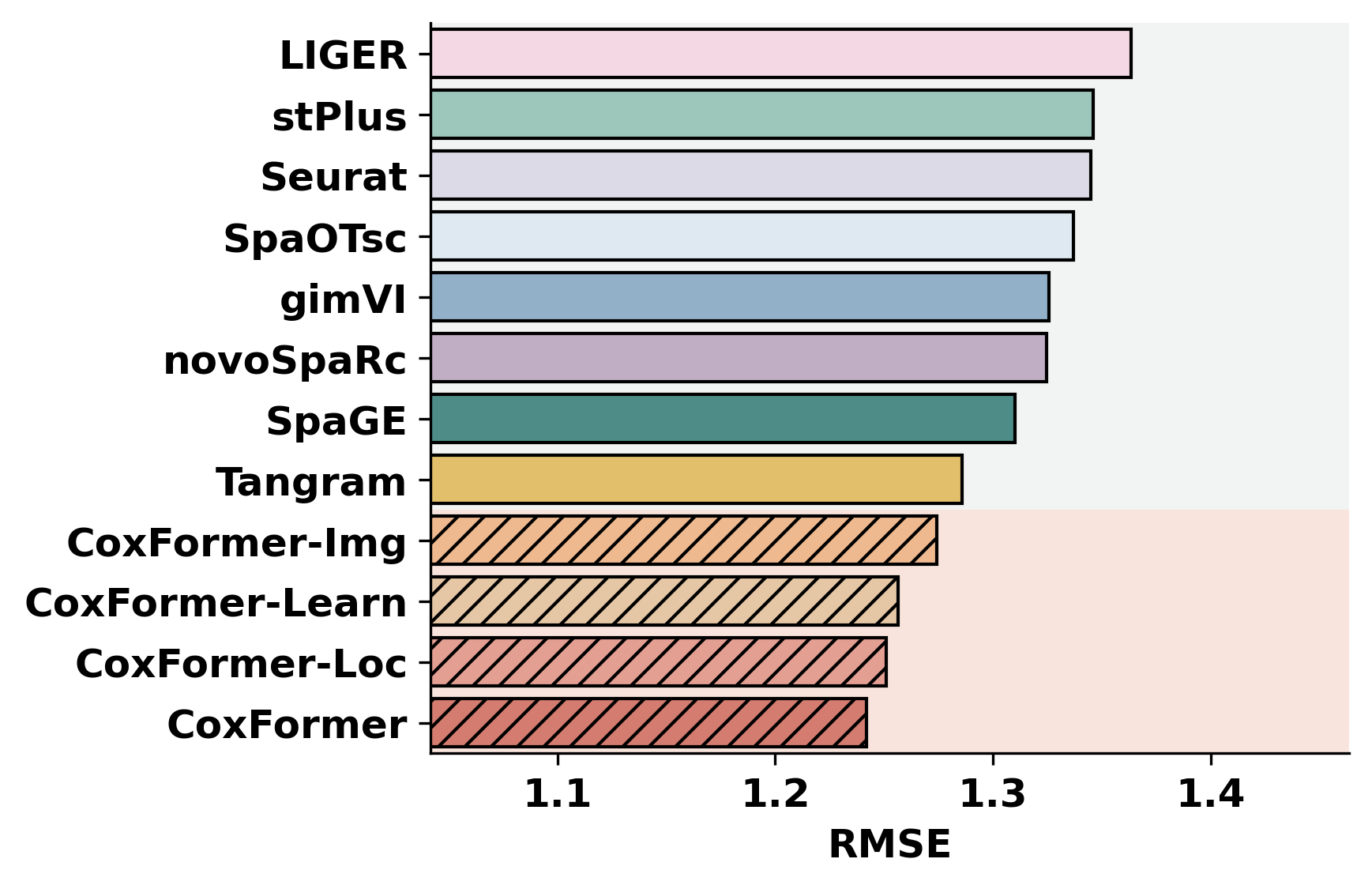
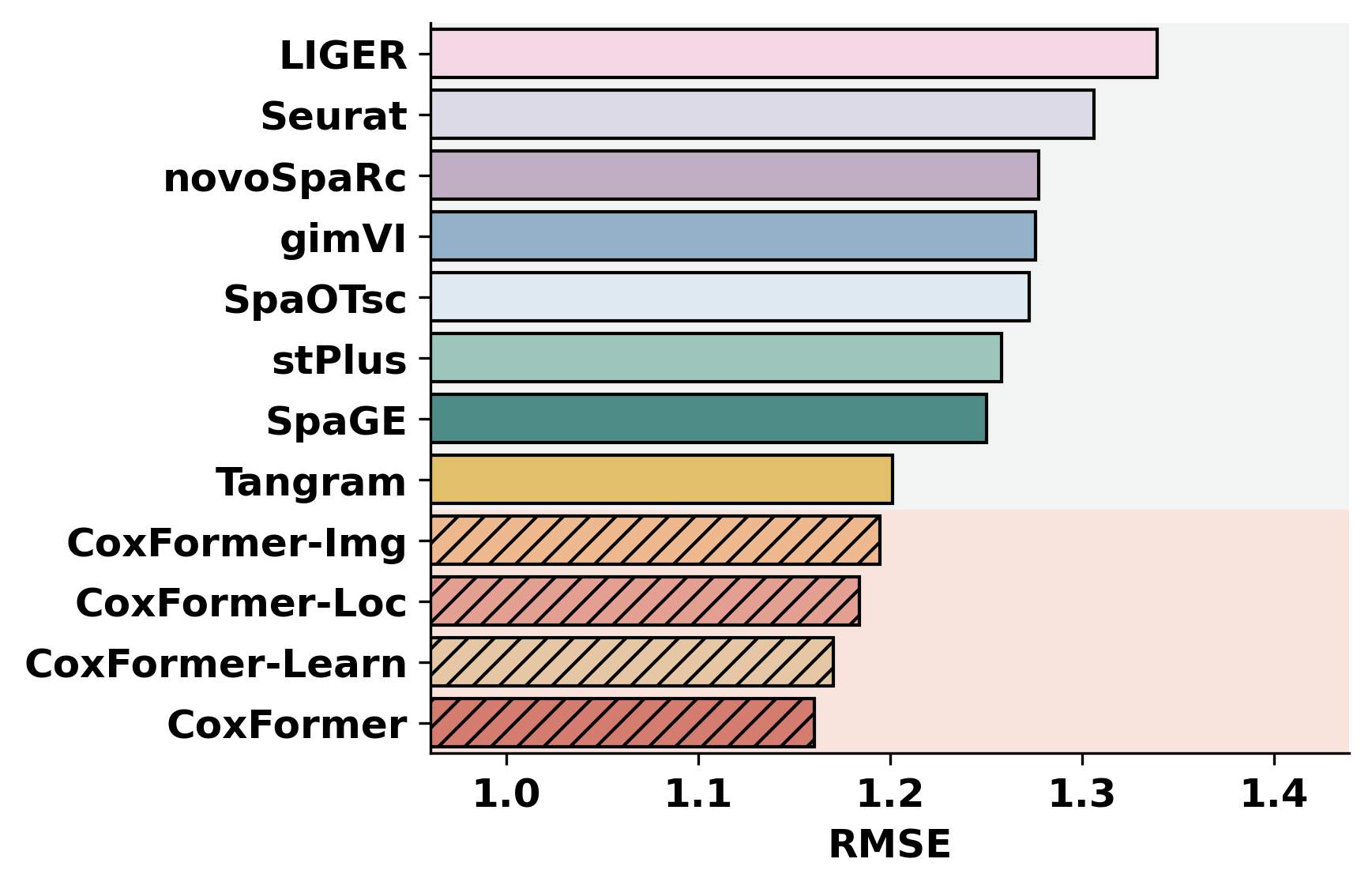
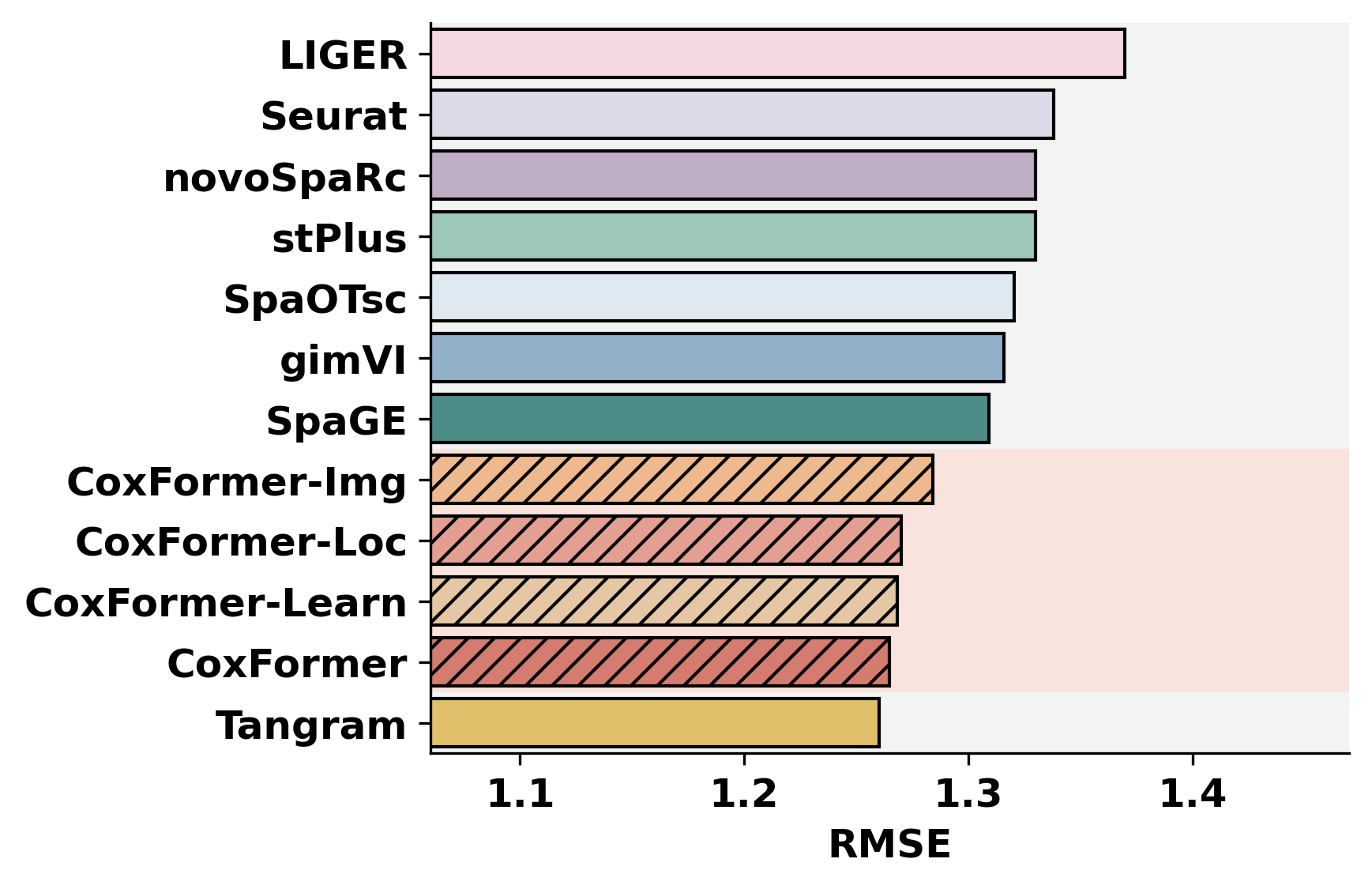
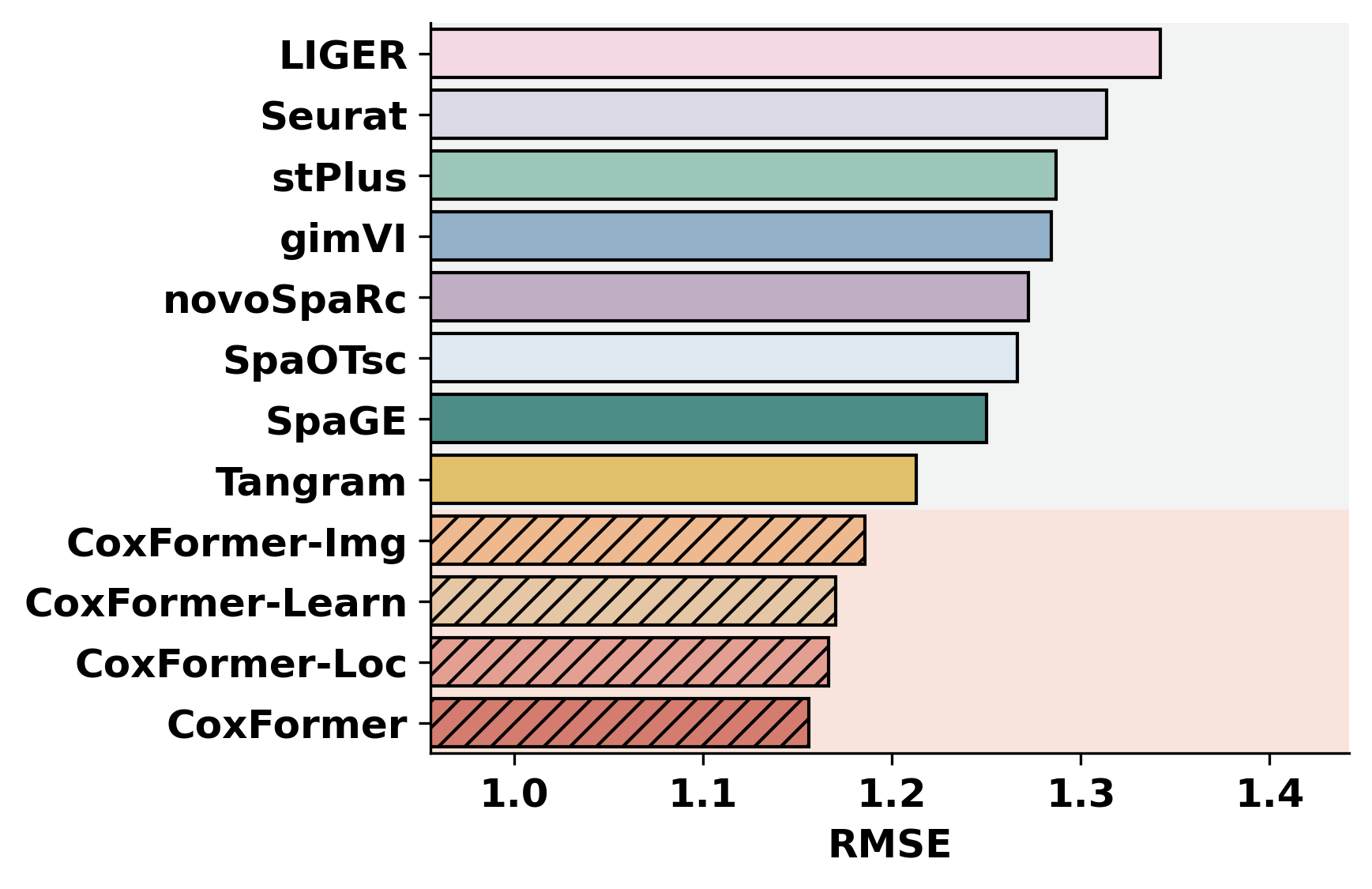
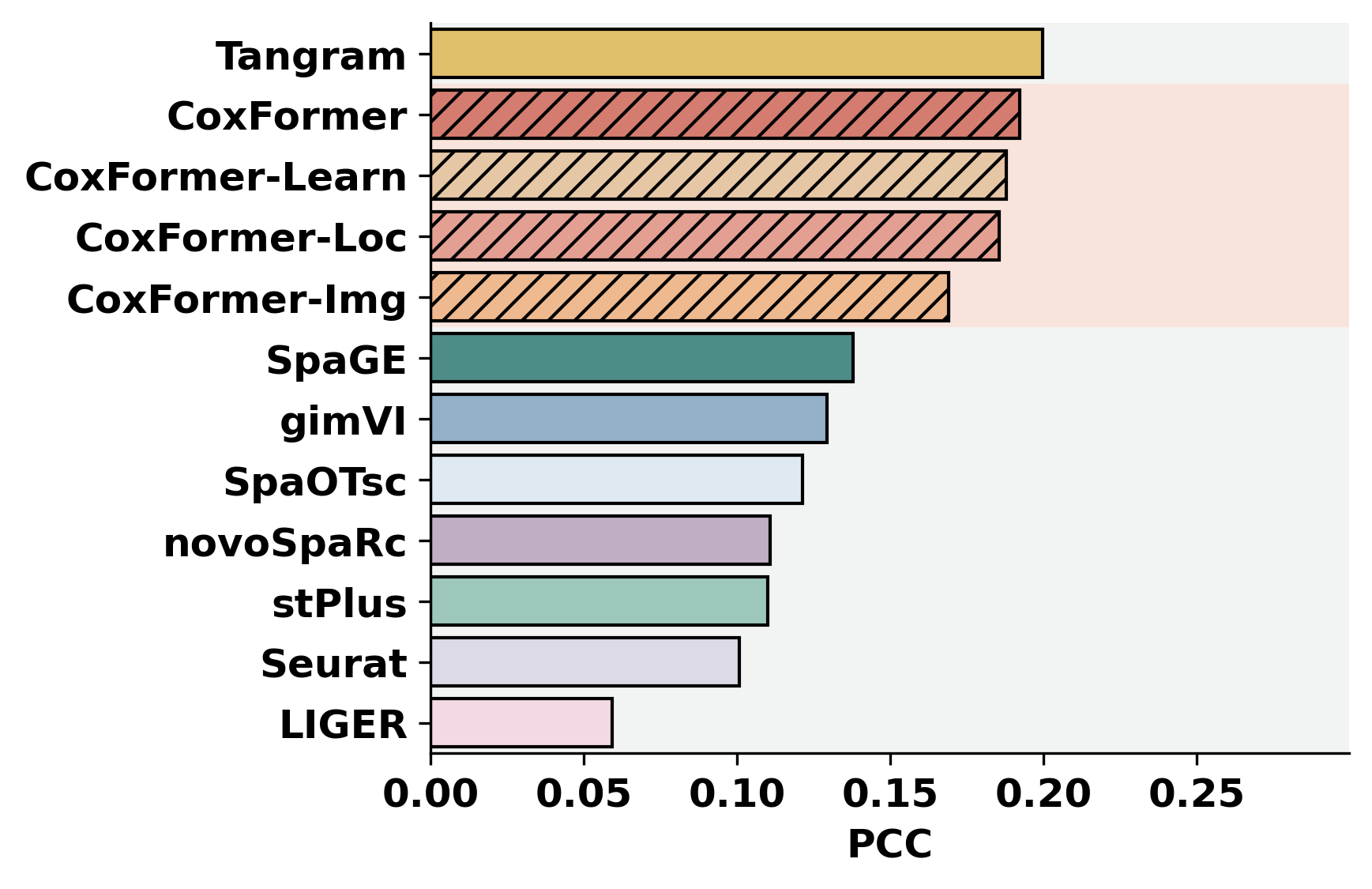
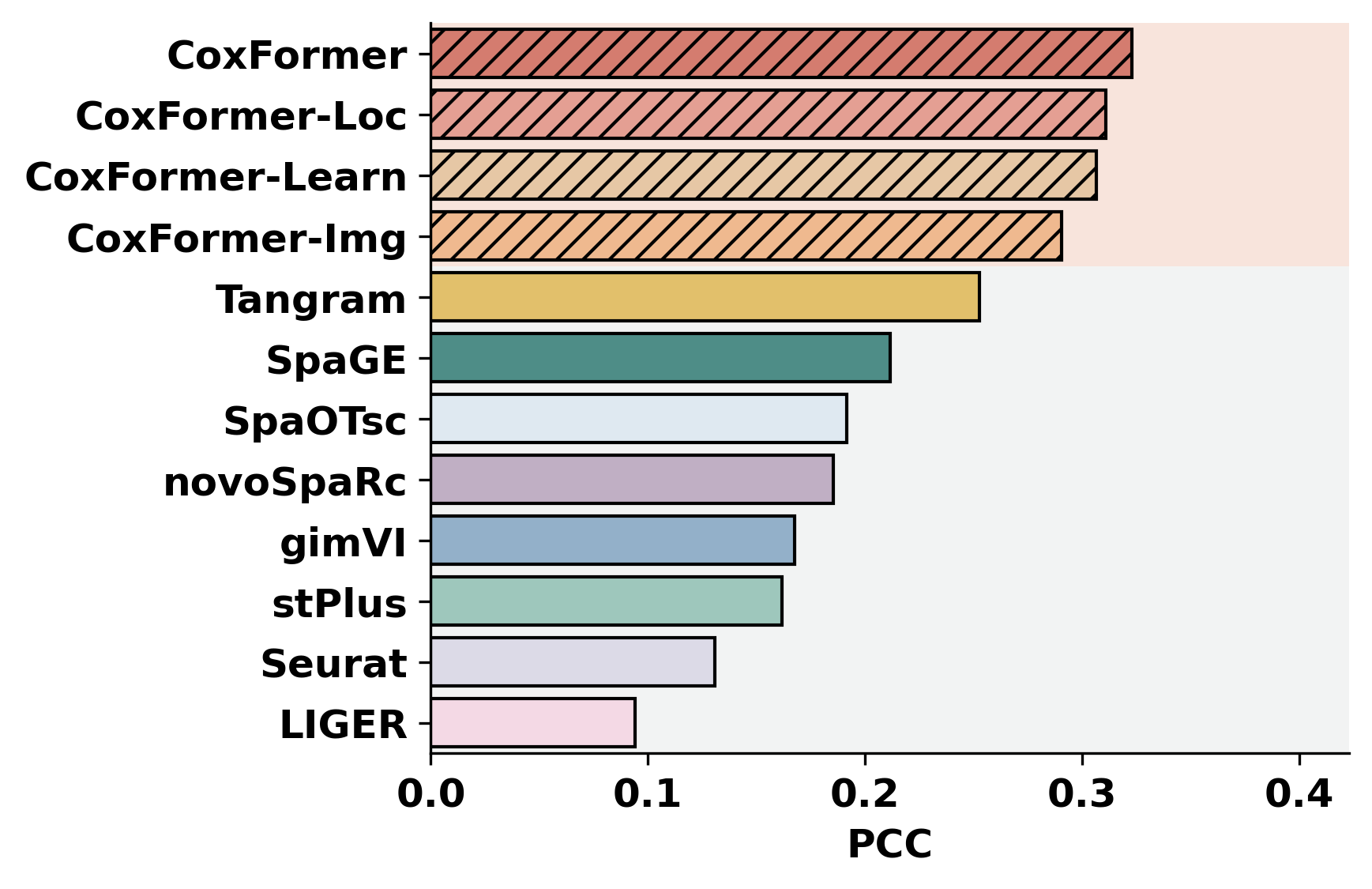
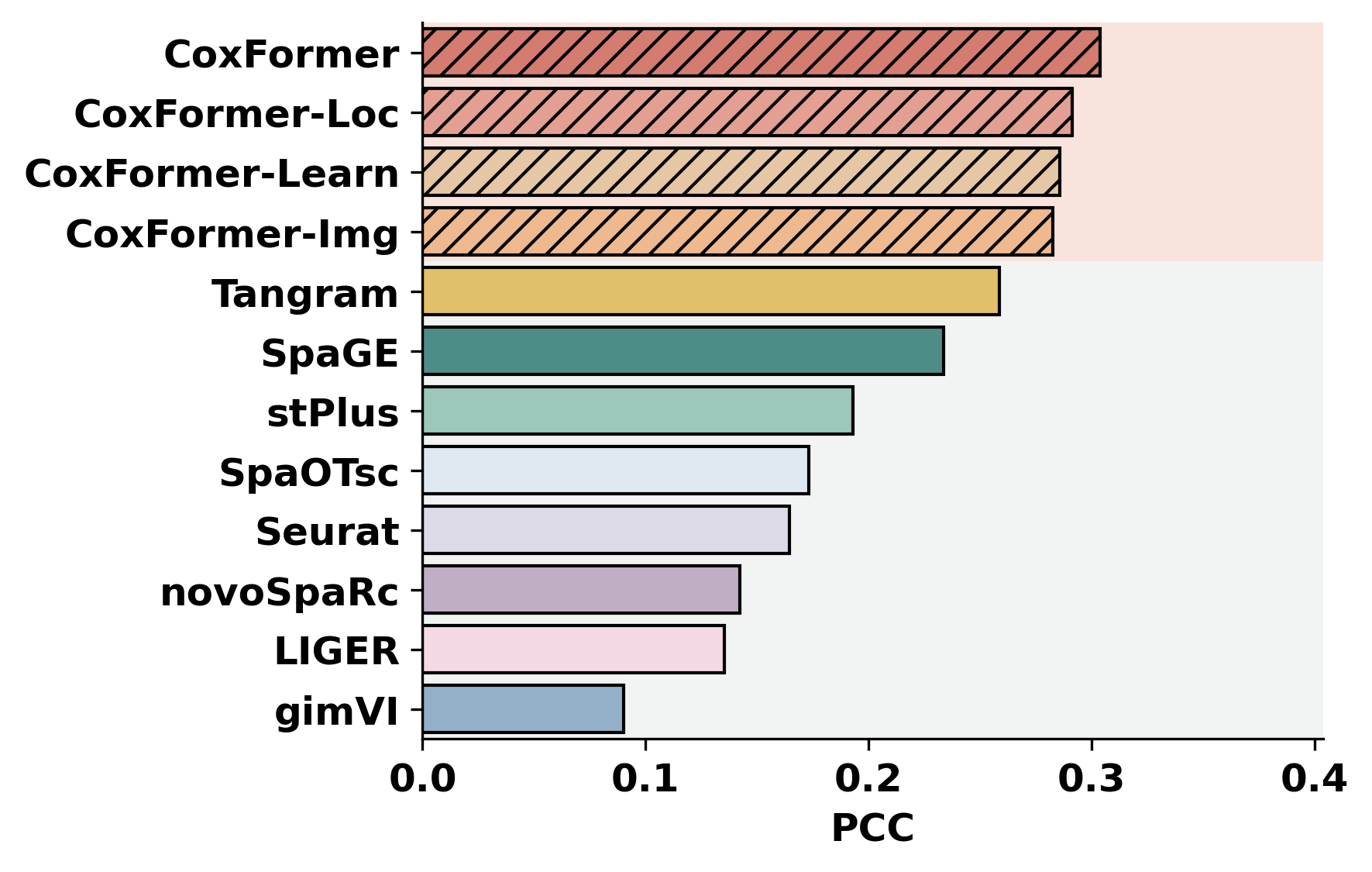
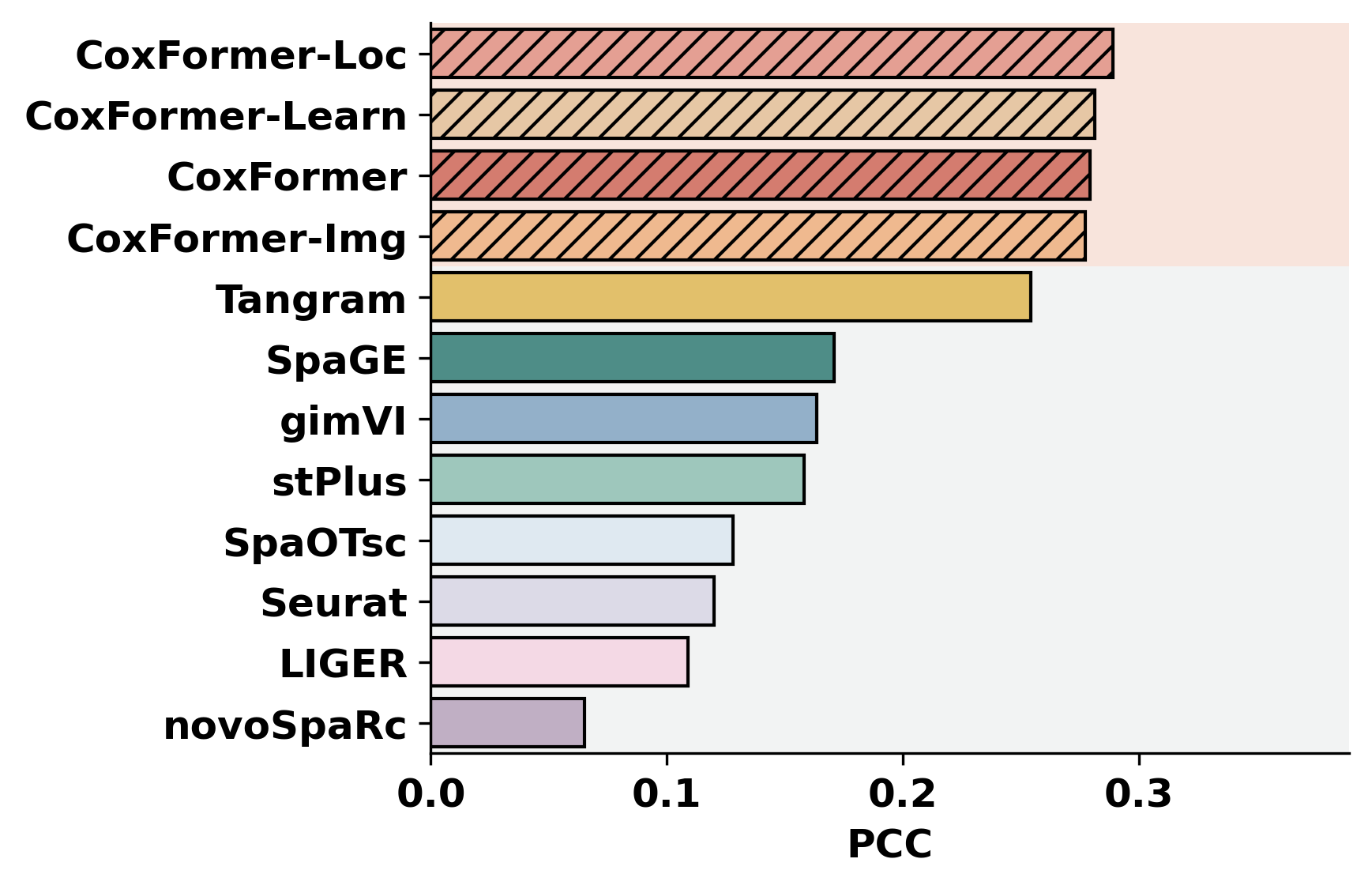
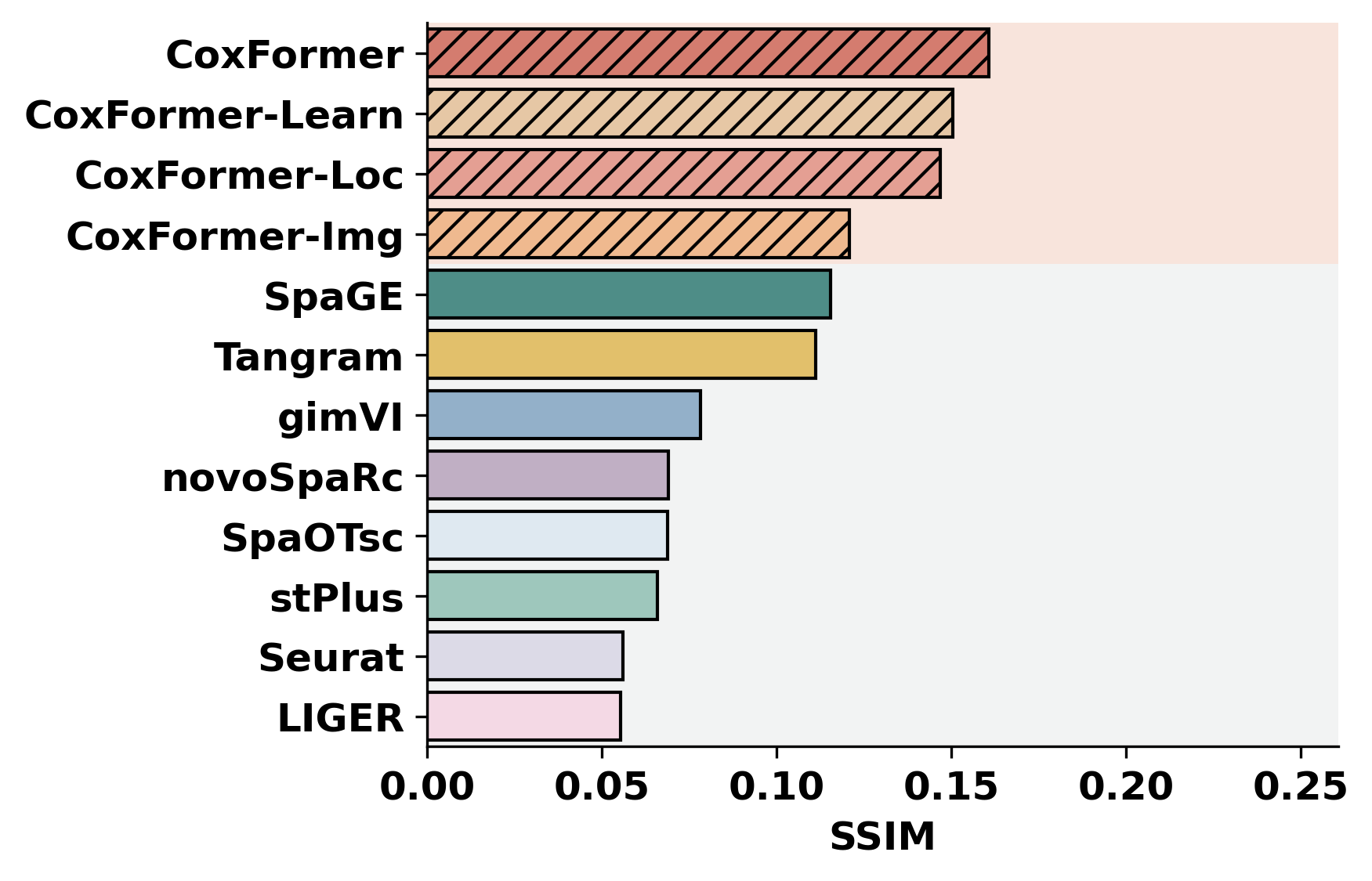
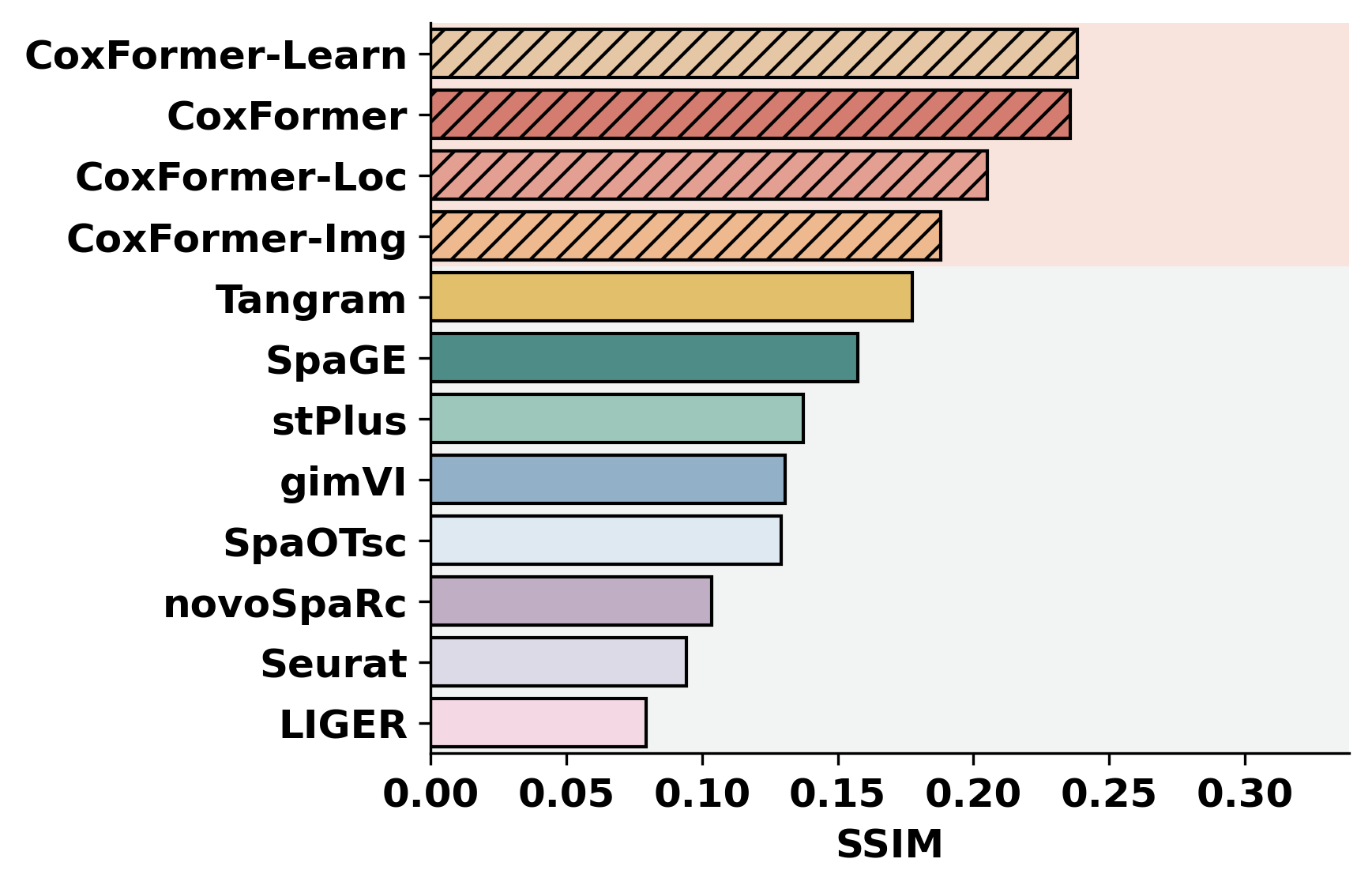

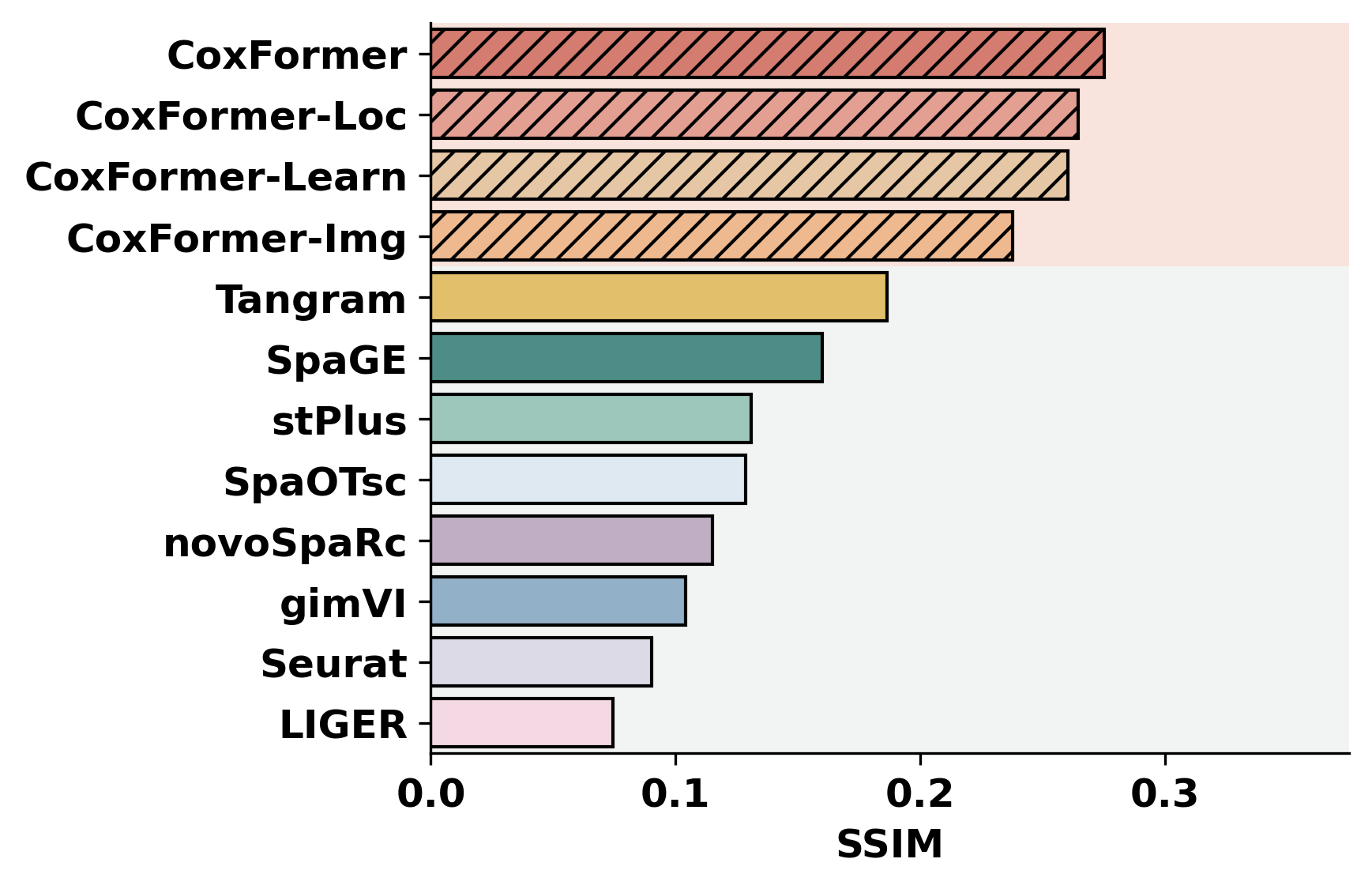
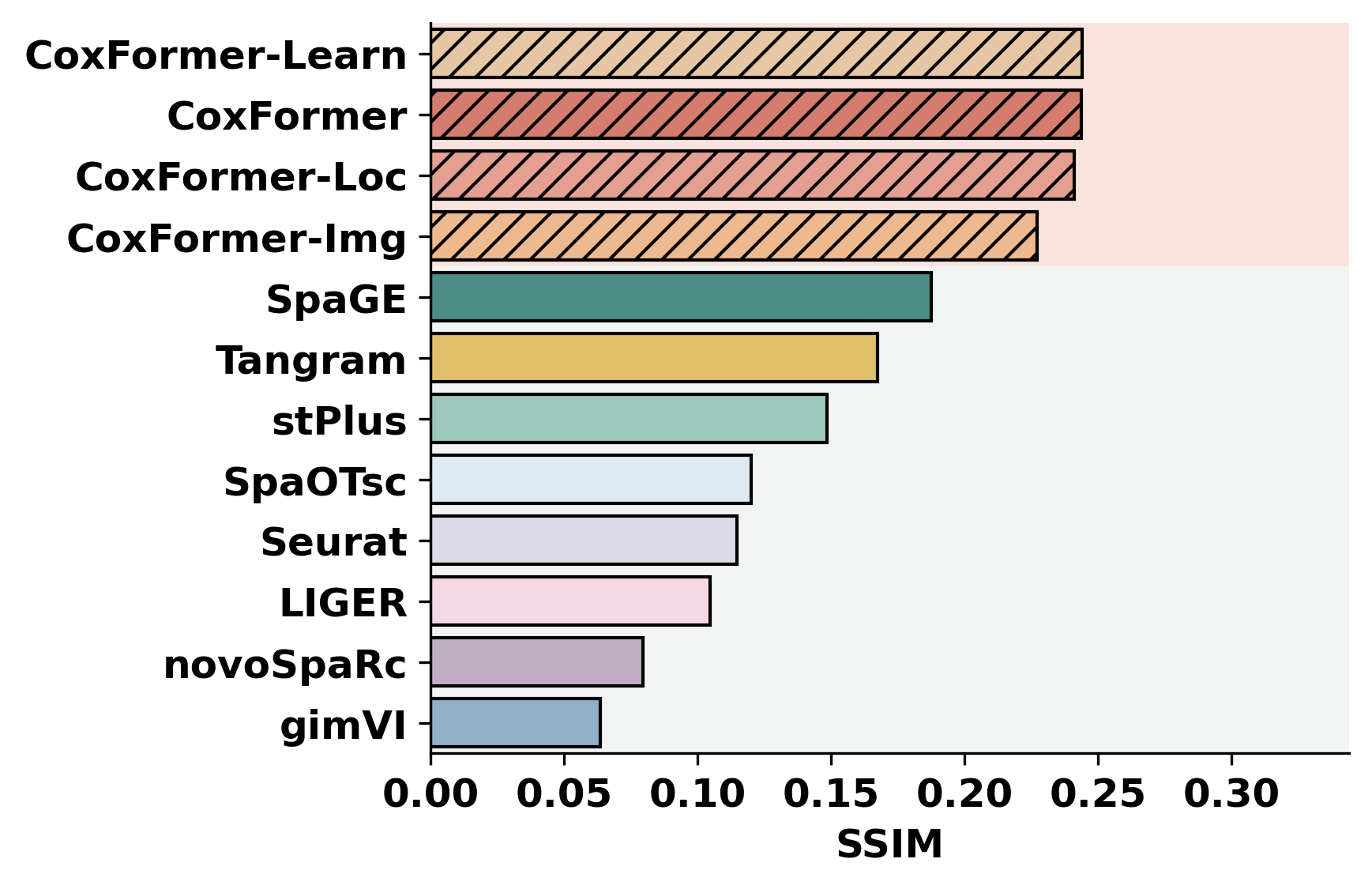
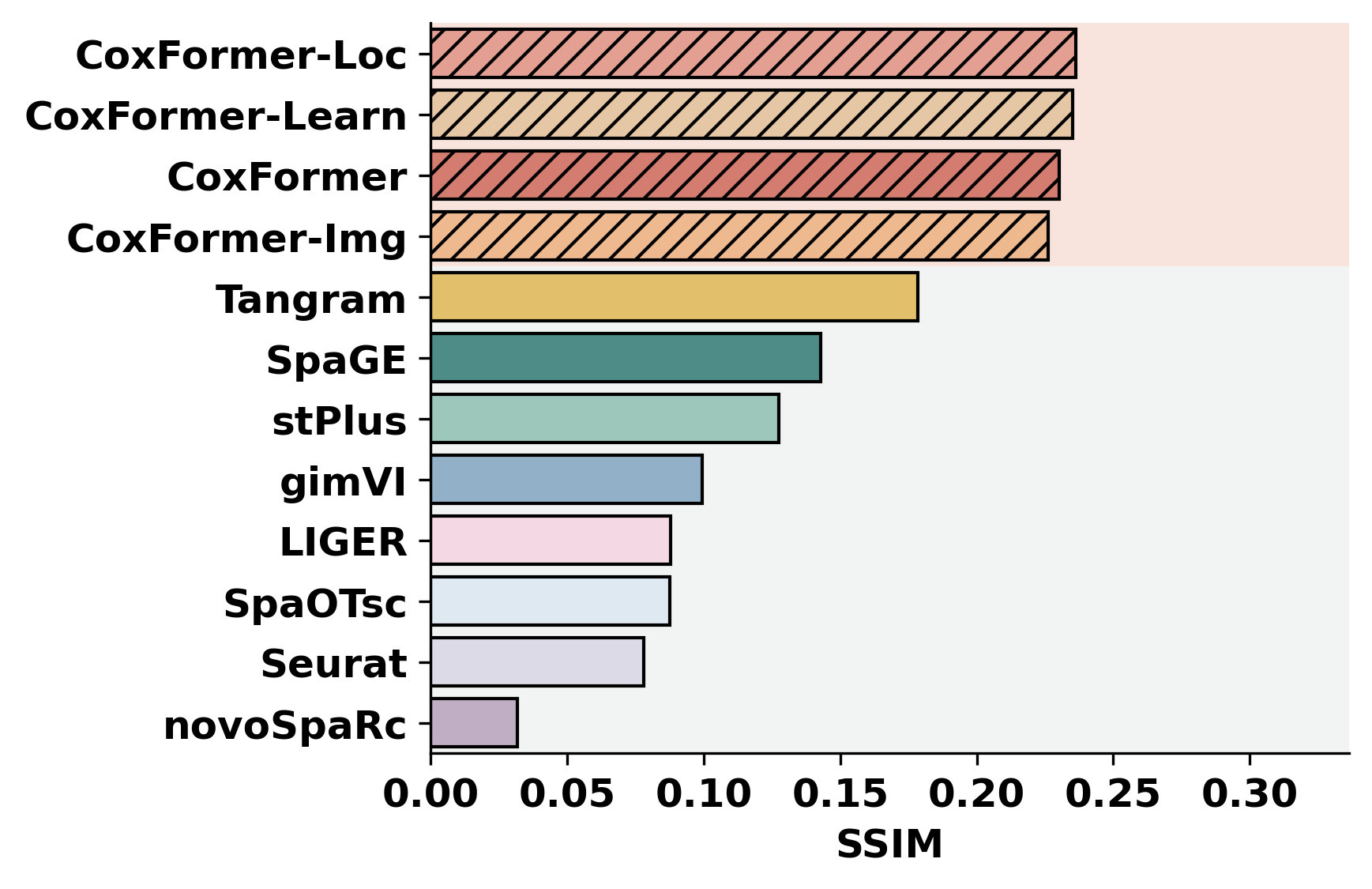
[ ]:
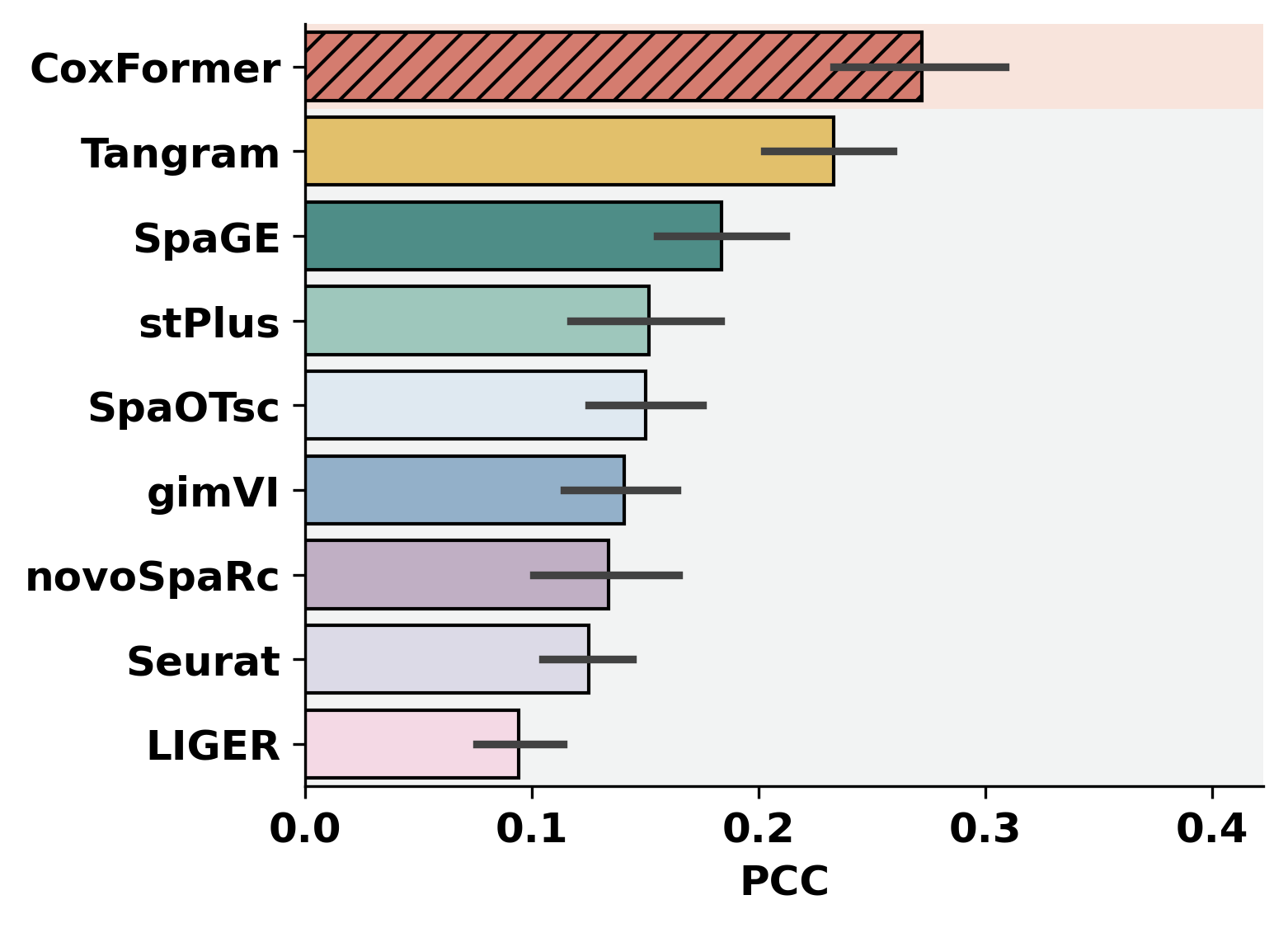
methods = ["CoxFormer", "SpaGE", "Tangram", "stPlus", "gimVI", "novoSpaRc", "LIGER", "Seurat", "SpaOTsc"]
metric_name = 'PCC'
paths = [os.path.join(RES_PATH, f"{dataset}") + os.sep for dataset in datasets]
plot_bar_benchmark(paths, metric_name, methods, RES_PATH, "benchmark-show", False)
3. Gene-level spatial visualization
This section visualizes spatial expression for a target gene on one or more datasets.
GroundTruth uses the ground truth (
groundtruth.csv).Each method uses its imputed output (
{METHOD}_impute.csv).The color scale is defined by the 1st/99th percentiles of the ground truth values for the target gene, and then reused for all methods.
The plot uses plot_gene_spatial / plot_spatial_scatter provided in utils.py.
[ ]:
methods = ["CoxFormer", "SpaGE", "Tangram", "stPlus", "gimVI", "novoSpaRc", "LIGER", "Seurat", "SpaOTsc"]
target_gene = "APOC1"
point_size = {"HBC6": 3.5, "HBC5": 3.5, "HBC4": 5.5, "HBC3": 5.5, "HBC2": 5.5, "HBC1": 5.5}
for dataset in datasets:
dataset_path = os.path.join(RES_PATH, dataset)
location = pd.read_csv(os.path.join(DATA_PATH, dataset, "locs.tsv"), sep="\t")
gt = pd.read_csv(os.path.join(dataset_path, "groundtruth.csv"))
gt.columns = gt.columns.str.strip().str.upper()
data = {"GroundTruth": pd.DataFrame({target_gene: gt[target_gene]})}
for m in methods:
fp = os.path.join(dataset_path, f"{m}_impute.csv")
if os.path.isfile(fp):
df = pd.read_csv(fp)
df.columns = df.columns.str.strip().str.upper()
if target_gene in df.columns:
data[m] = pd.DataFrame({target_gene: df[target_gene]})
plot_gene_spatial(
gene_list=[target_gene],
location=location,
data=data,
save_dir=dataset_path,
prefix=f"{target_gene}",
layout="single_row",
methods=list(data.keys()),
ncols=len(data),
per_ax=1.7,
dpi=300,
cmap="viridis",
s=point_size[dataset],
add_colorbar=False,
)





